
RAG Basics: Querying earnings transcripts
Retrieval-augmented generation on an Apple earnings call

Let’s review a simple example of how RAG works with LLM. Apple just reported earnings, and you want to know information like “What was iPhone revenue this quarter?” The transcript is 46,000 characters. You could read the whole thing. Or you could ask an LLM.
But the LLM has never seen this transcript. It was trained months ago. It has no idea what Apple reported last week. So how do you give it the information it needs without dumping 46,000 characters into the prompt?
More broadly, how can we ask questions against some text?
That’s what RAG does. Retrieval-Augmented Generation. It sounds fancy, but the core idea is simple: find the relevant pieces of a document, hand them to the LLM, and let it answer.
The whole thing is about 100 lines of Python. No frameworks. No vector databases. No LangChain. Just the raw mechanics, step by step.
The Source: An Earnings Call Transcript
We’re working with Apple’s Q4 FY2025 earnings call transcript.
“Good afternoon, and welcome to the Apple Q4 Fiscal Year 2025 Earnings Conference Call. Today, Apple is proud to report $102.5 billion in revenue, up 8% from a year ago and a new September quarter record...”
It goes on for about 8,000 words. Tim Cook gives prepared remarks, the CFO walks through financials, then analysts ask questions. Typical earnings call structure. You can read the full thing on Yahoo Finance or Motley Fool.
If we paste this entire transcript into a prompt, we’re wasting tokens on irrelevant sections (the legal disclaimer, the operator instructions, the analyst chitchat). We want to find just the parts that answer our question.
Chunking: Splitting the Document
First, we break the transcript into smaller pieces. Each piece is roughly 500 characters, about the length of a short paragraph. When a paragraph is longer than that, we split it with some overlap so we don’t lose context at the boundaries.
For this transcript, that gives us about 100 chunks. Each one is a self-contained snippet: one might be Tim Cook talking about iPhone, another might be the CFO discussing services revenue, another might be an analyst asking about China.
The tradeoff is straightforward. Chunks too small, and you lose context. “Revenue was $49 billion” means nothing without knowing it’s about iPhone. Chunks too large, and you dilute the signal with irrelevant text. 500 characters is a reasonable middle ground for earnings calls.
Embeddings: Turning Text into Numbers
Now we need a way to compare our question to each chunk. Computers can’t compare sentences directly, so we convert them into numbers.
An embedding model takes a piece of text and produces a list of numbers. “iPhone set a revenue record at $49 billion” becomes something like [0.038, -0.021, 0.087, 0.015, -0.044, ...]. The model was trained so that texts about similar topics produce similar lists of numbers.
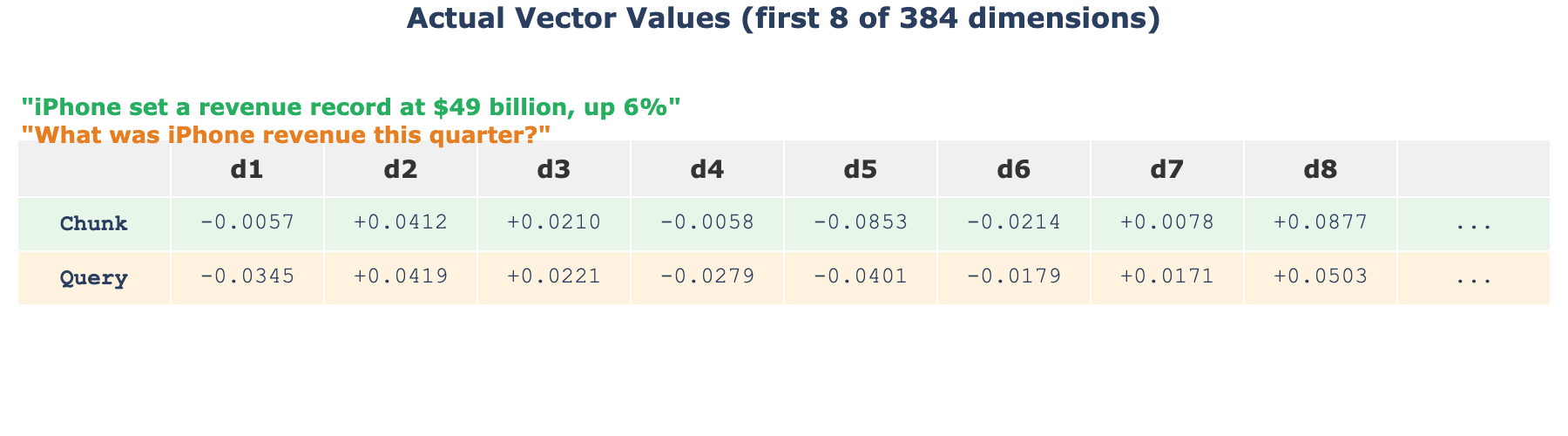
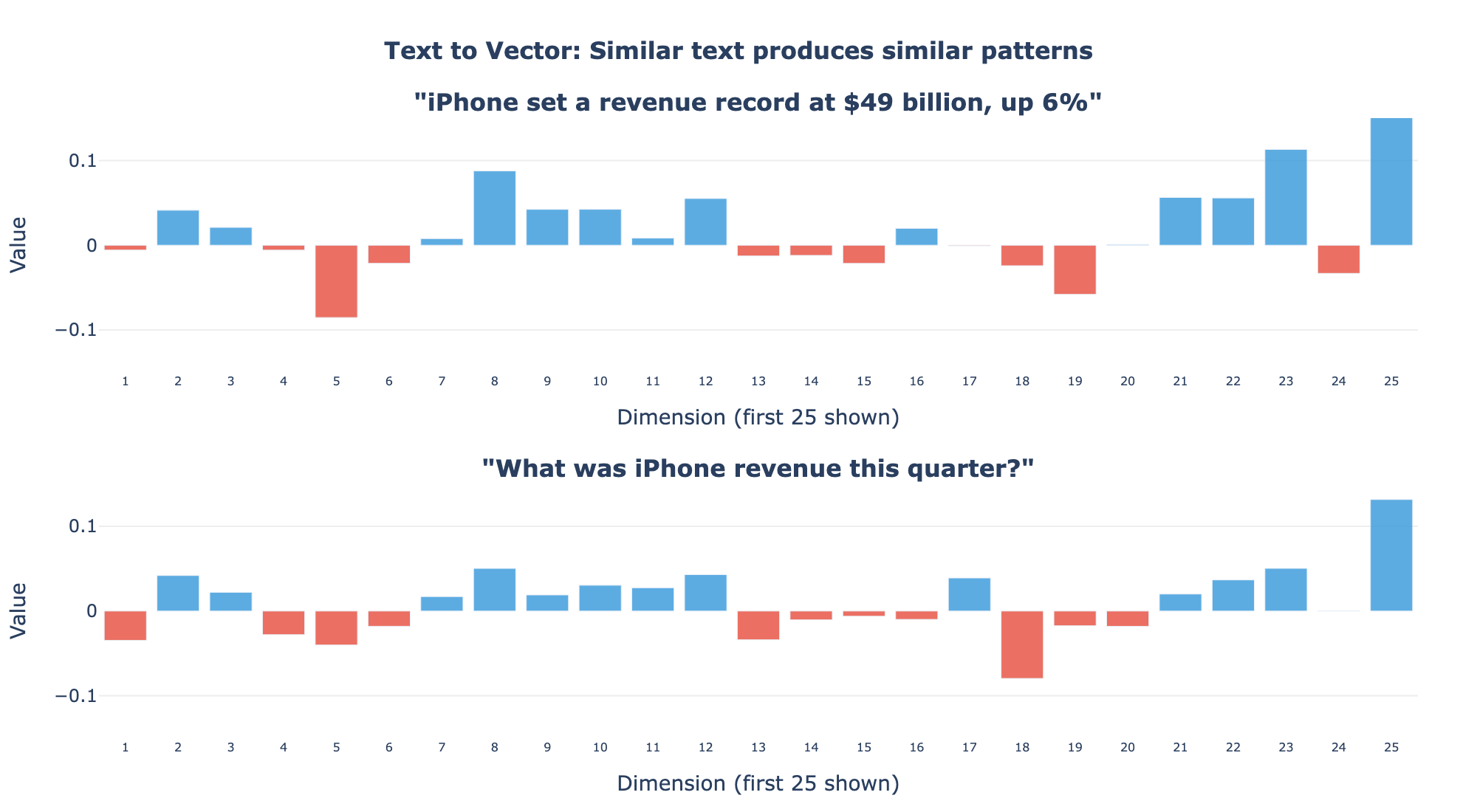
We run every chunk through the same model. Each chunk becomes a list of numbers. Our question, “What was iPhone revenue this quarter?”, also becomes a list of numbers through the same model.
The key idea: because the model was trained on enormous amounts of text, it learned to place “iPhone revenue was $49 billion” and “What was iPhone revenue?” near each other in this number space. They’re about the same topic, so their numbers are similar.
Cosine Similarity: Measuring Closeness
How do we measure “similar”? We use cosine similarity. Think of each list of numbers as an arrow pointing in some direction. Two arrows pointing in nearly the same direction have high cosine similarity (close to 1.0). Two arrows pointing in completely different directions have low cosine similarity (close to 0).
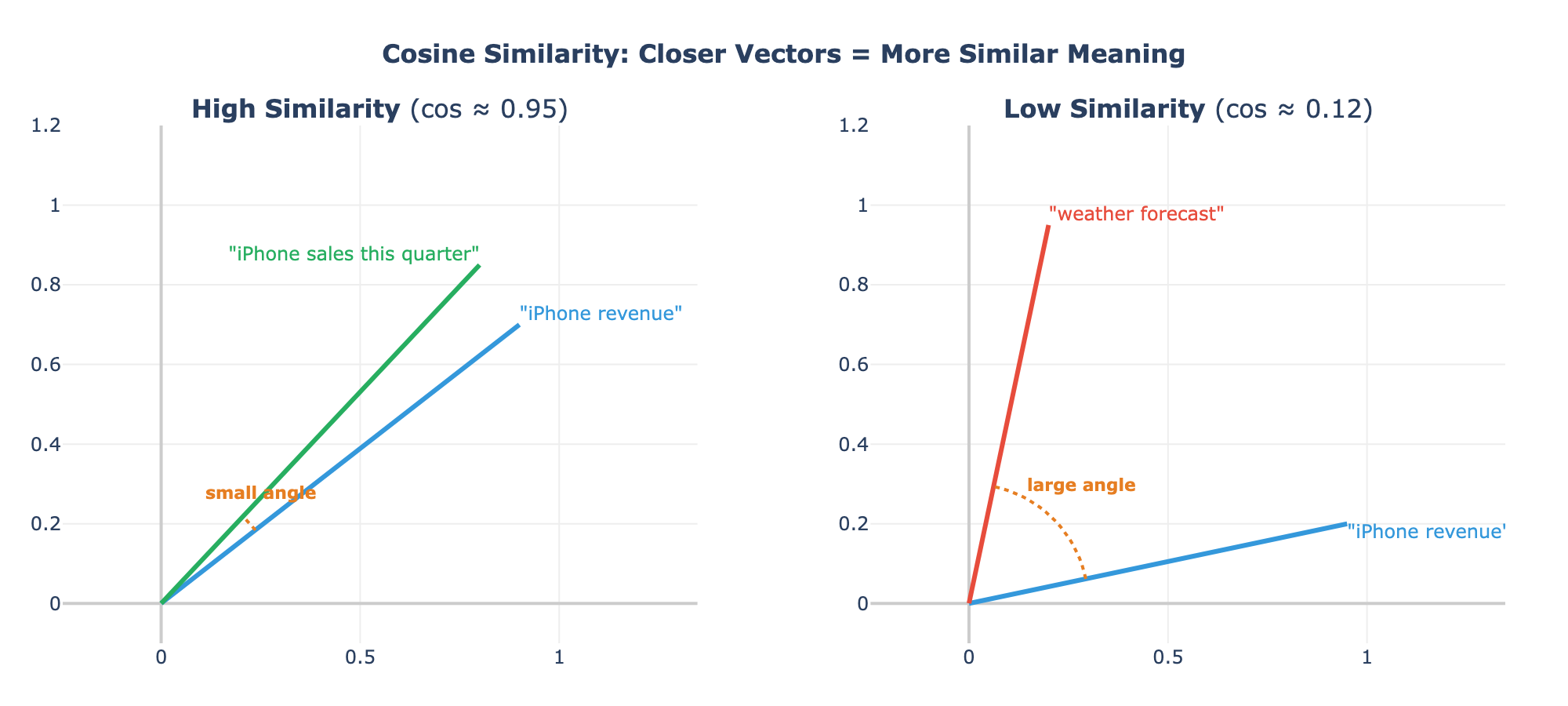
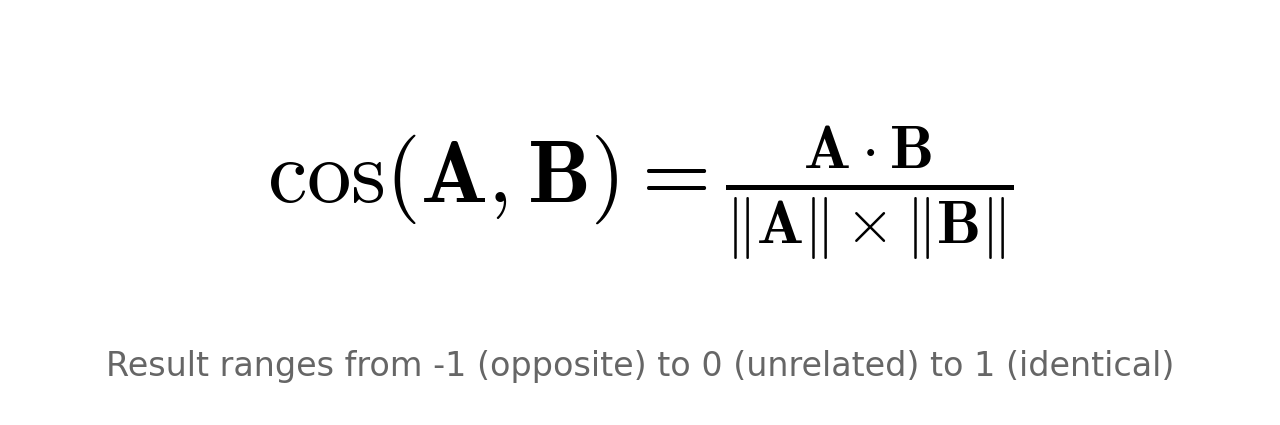
The math is a dot product divided by the magnitudes. For our question and the iPhone revenue chunk: multiply each pair of matching numbers, add them up, divide by the lengths. The result: 0.92. Very similar.
For a chunk about something unrelated, like the legal disclaimer, the score might be 0.15. The numbers point in different directions because the topics have nothing in common.
We compute this score between our question and every single chunk. Then we take the top 3.
Where Similarity Gets It Wrong
This is worth pausing on. The highest-scoring chunk is not always the one with the answer. In our case, the chunk about forward guidance (”We expect revenue to grow 10-12%”) scored higher than the chunk that actually contains “$49 billion.” Why? Because the guidance chunk mentions “revenue” and “quarter” repeatedly, the same words as our question.
Cosine similarity measures word overlap in meaning, not whether the chunk answers the question. This is a real limitation. The system finds related text, not necessarily the right text.
But it doesn’t matter too much, because we send the top 3 chunks to the LLM, not just the top 1. As long as the answer is somewhere in those 3, the LLM can find it.
Generation: The LLM Reads and Answers
We take the top 3 chunks and build a prompt:
Context (from the earnings call):
- “iPhone set a revenue record at $49 billion, up 6% from a year ago, with growth in most markets...”
- “Apple is proud to report $102.5 billion in revenue, up 8%...”
- “We expect December quarter revenue to grow 10-12%...”
Question: What was iPhone revenue this quarter?
Answer using only the context above.
We send this to Claude. The LLM reads all three chunks, identifies the specific fact, and produces:
“iPhone revenue was $49 billion this quarter, up 6% year over year.”
Grounded in the transcript. Not hallucinated. The LLM didn’t need to know this from training. We gave it the information at query time.
The Full Pipeline (Animated)
The animation below walks through every step: starting from the raw transcript, splitting into chunks, converting to numbers, computing similarity, ranking, and generating the final answer.

Where RAG Breaks Down
RAG is not magic. It breaks in predictable ways.
Bad chunking is the most common failure. If a chunk splits a sentence in half, the embedding model sees a fragment without context. “Revenue was” in one chunk and “$49 billion from iPhone” in another. Neither chunk alone answers the question well.
Ambiguous questions cause problems too. “How did Apple do?” could match almost everything in the transcript. The retrieval returns generic chunks about overall performance, missing the specific detail you wanted.
And sometimes the LLM ignores the context anyway. You hand it three relevant chunks and it hallucinates a number that appears nowhere in the transcript. This happens less with explicit instructions (”answer using only the context above”) but it still happens.
Production systems address these issues with re-ranking, hybrid search, and better chunking strategies. But the core loop is exactly what we built: chunk, embed, retrieve, generate.
#AI #NLP #RAG